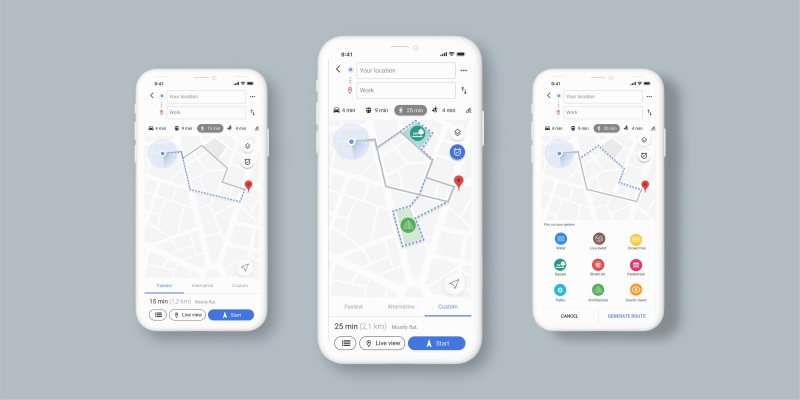
Van onze klant River Cleanup, kregen we de opdracht om een groeiend aantal registraties van afval van gebruikers te visualiseren op Google Maps.
Elke registratie bevat een geotagged foto van afval.
Met deze foto's verdienen gebruikers punten, stijgen ze in de ranglijsten en krijgen in specifieke actiegebieden zelfs dubbele punten.
Maar met potentieel tienduizenden registraties liep de traditionele aanpak, waarbij alle coördinaten in de browser werden ingevoerd en de JavaScript-clustering van Google Maps dit afhandelde, al snel vast.
Dus ontwikkelden we iets slimmers: server-side clustering met Laravel, Vue.js, geohashing en Meilisearch.
Waarom server-side clustering?
Het probleem was niet alleen esthetisch, maar vooral technisch:
- Prestaties: het tonen en clusteren van duizenden markers in de browser heeft een stevige performantie impact
- Gegevensoverdracht: het verzenden van alle puntgegevens naar de client is niet schaalbaar
- Realtime UX: we wilden dat clusters zouden worden bijgewerkt wanneer gebruikers de kaart verschuiven, zonder hun computer of smartphone te overbelasten
- Volume: met duizenden registraties, hebben we een systeem nodig dat schaalbaar is
Prestaties: het tonen en clusteren van duizenden markers in de browser heeft een stevige performantie impact
Gegevensoverdracht: het verzenden van alle puntgegevens naar de client is niet schaalbaar
Realtime UX: we wilden dat clusters zouden worden bijgewerkt wanneer gebruikers de kaart verschuiven, zonder hun computer of smartphone te overbelasten
Volume: met duizenden registraties, hebben we een systeem nodig dat schaalbaar is
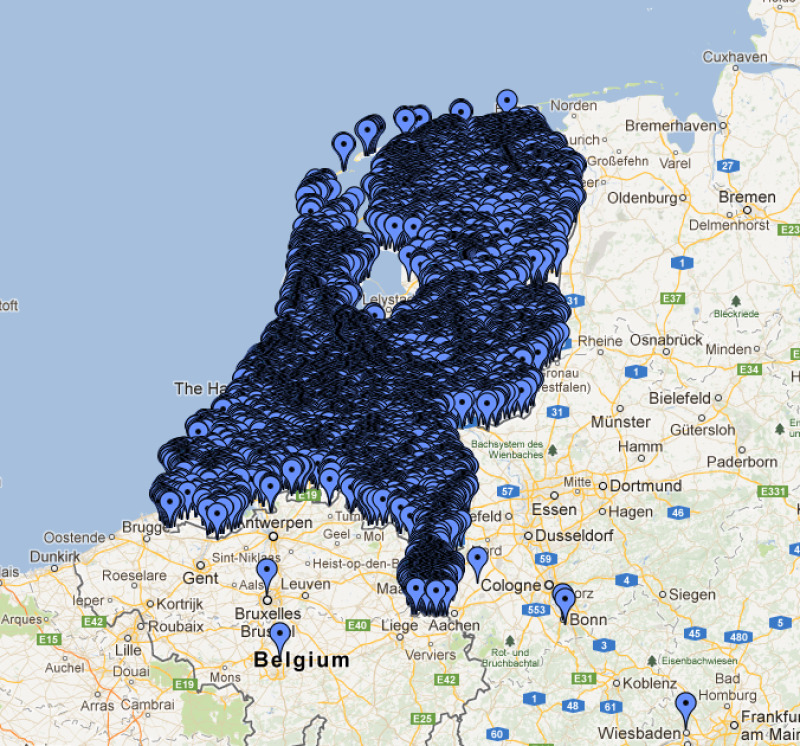
Hoe wij het hebben opgelost
We gebruikten geohashing om nabijgelegen punten te groeperen met verschillende precisieniveaus.
Een geohash is een korte alfanumerieke string die een geografische locatie codeert. Wat geohashes bijzonder nuttig maakt voor clustering, is hun hiërarchische aard: elk extra teken in de geohash verhoogt de precisie en verfijnt de locatie.
De geohash u173z7 is bijvoorbeeld een nauwkeurigere locatie binnen het grotere gebied dat wordt gedefinieerd door u173, enzovoort.
Deze eigenschap stelt ons in staat om items dynamisch te groeperen, afhankelijk van het zoomniveau. Kortere hashes vertegenwoordigen grotere clusters, langere hashes zoomen in op fijnere details.
Elke nieuwe foto-registratie wordt gegeotaggd en opgeslagen als een watcher_entry. Van daaruit genereren we clusters en slaan deze op in een aparte geo_clusters-tabel met behulp van het pakket beste/latlon-geohash package.

Elk item genereert 12 clusterrecords, één voor elk geohashniveau (van 1 tot 12). Met 10.000 foto-uploads beheren we dus ongeveer 100.000 geo_cluster-items.
Elk cluster bevat:
- De geohash
- Zoomniveau (hash_length)
- Aantal punten in die cluster
- Een berekend zwaartepunt (breedtegraad/lengtegraad)
De geohash
Zoomniveau (hash_length)
Aantal punten in die cluster
Een berekend zwaartepunt (breedtegraad/lengtegraad)
Bij het verplaatsen of zoomen van de kaart vraagt de Vue.js-frontend alleen de relevante clusters op bij de search index Meilisearch. Met behulp van de geosearch functionaliteit worden items binnen de kaartgrenzen en een overeenkomende hashlengte geselecteerd.
Het resultaat? Een snelle, schaalbare kaart die op elk zoomniveau betekenisvolle clusters weergeeft, zonder de lokale browser op de bezoeker zijn toestel te overbelasten.
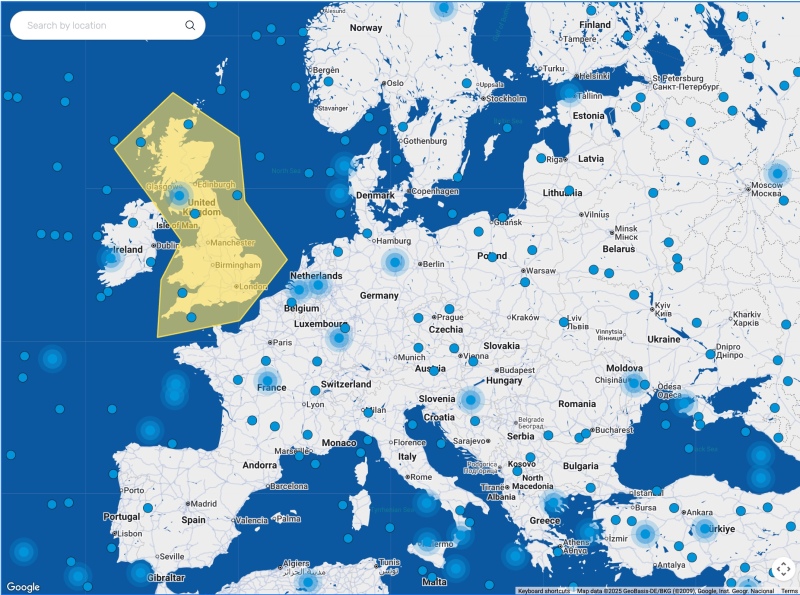
De technologie achter de schermen
Dit zijn de verschillende onderdelen:
- Laravel Observers: wanneer een watcher_entry wordt toegevoegd, werkt een observer de geo_clusters-tabel dienovereenkomstig bij, waarbij de clustergroottes worden verhoogd en de zwaartepunten opnieuw worden berekend.
- Meilisearch: clusters worden geïndexeerd en doorzocht met behulp van de snelle geo search functie.
- Vue.js & Google Maps: de frontend zoekt naar het zichtbare gebied en rendert clusters op basis van zoom.
- Filament Admin Panel: wordt gebruikt om items te beheren, "bonuszones" te tekenen en updates te activeren.
Laravel Observers: wanneer een watcher_entry wordt toegevoegd, werkt een observer de geo_clusters-tabel dienovereenkomstig bij, waarbij de clustergroottes worden verhoogd en de zwaartepunten opnieuw worden berekend.
Meilisearch: clusters worden geïndexeerd en doorzocht met behulp van de snelle geo search functie.
Vue.js & Google Maps: de frontend zoekt naar het zichtbare gebied en rendert clusters op basis van zoom.
Filament Admin Panel: wordt gebruikt om items te beheren, "bonuszones" te tekenen en updates te activeren.
We hebben ook een aangepast Filament-veld gemaakt waarmee beheerders zelf polygone zones op de kaart kunnen tekenen. Deze zones geven dubbele score voor registraties die binnen deze zones worden ingediend. Om te detecteren of een item binnen een dergelijke zone valt, gebruiken we het pakket mjaschen/phpgeo package.
Beperkingen
Geen enkel systeem is zonder nadelen. Hoewel server-side clustering de prestaties en schaalbaarheid aanzienlijk verbetert, brengt het ook enkele nieuwe uitdagingen met zich mee:
- Filter complexiteit: fine-grained filtering, zoals het alleen weergeven van items van een specifieke gebruiker, periode of status, wordt complexer. Omdat clusters vooraf worden berekend en niet gekoppeld zijn aan dynamische queryparameters, betekent het toepassen van gedetailleerde filters dat de clusterlogica opnieuw moet worden berekend of volledig moet worden omzeild.
- Herladen bij kaartverplaatsing: elke pan- of zoomgebeurtenis activeert een volledige herlading van de clustergegevens. Dit zorgt ervoor dat de kaart nauwkeurig blijft, maar kan leiden tot kleine laadvertragingen bij tragere verbindingen.
- Initieel laden in nieuwe gebieden: bij het uitzoomen of springen naar een andere regio kan er een kort moment zijn waarop geen clusters worden weergegeven totdat nieuwe gegevens worden opgehaald.
Filter complexiteit: fine-grained filtering, zoals het alleen weergeven van items van een specifieke gebruiker, periode of status, wordt complexer. Omdat clusters vooraf worden berekend en niet gekoppeld zijn aan dynamische queryparameters, betekent het toepassen van gedetailleerde filters dat de clusterlogica opnieuw moet worden berekend of volledig moet worden omzeild.
Herladen bij kaartverplaatsing: elke pan- of zoomgebeurtenis activeert een volledige herlading van de clustergegevens. Dit zorgt ervoor dat de kaart nauwkeurig blijft, maar kan leiden tot kleine laadvertragingen bij tragere verbindingen.
Initieel laden in nieuwe gebieden: bij het uitzoomen of springen naar een andere regio kan er een kort moment zijn waarop geen clusters worden weergegeven totdat nieuwe gegevens worden opgehaald.
Deze beperkingen zijn acceptabel in onze huidige context, maar we bekijken pistes om dit nog te verbeterern, zoals hybride client/server-clustering of prefetching van achtergrondgegevens, om de gebruikerservaring op een nog hoger niveau te krijgen.
Besluit
Door gebruikers gegenereerde kaartgegevens zijn krachtig, maar efficiënte verwerking ervan vereist meer dan alleen goede frontendcode.
Door clusterlogica naar de server te pushen, kunnen we grote datasets soepel verwerken en op elk apparaat een betere ervaring bieden.
En belangrijker nog, we bieden gebruikers een gamified, lonende manier om hun wereld een beetje schoner te maken.