As part of our ongoing work for river-cleanup.org, we were tasked with visualizing a growing number of user-submitted trash reports on a Google Map.
Each report includes a geotagged photo of trash found near a river. These photos earn users tokens, allow them to climb leaderboards, and in some areas, even earn double points.
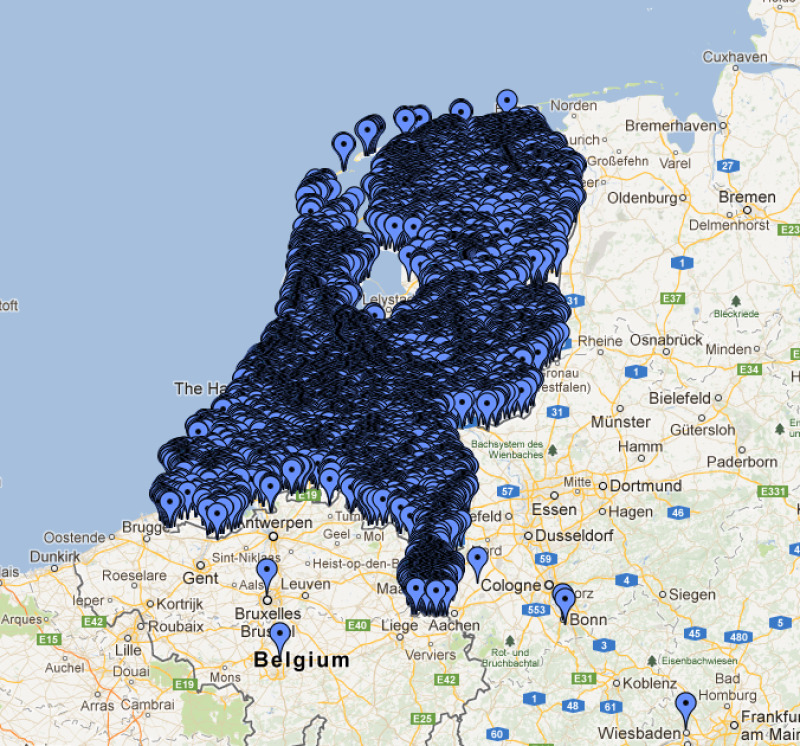
But with potential tens of thousands of reports, the traditional approach of dumping all coordinates into the browser and letting Google Maps’ JavaScript clustering handle it quickly broke down.
So we built something smarter: server-side clustering using Laravel, Vue.js, geohashing, and Meilisearch.
Why server-side clustering?
The problem wasn’t just aesthetic, it was technical:
- Performance: Rendering and clustering thousands of markers in the browser severely impacts JS performance.
- Data transfer: Sending all point data to the client isn’t scalable.
- Real-time UX: We wanted clusters to update as users moved the map, without overloading their device.
- Volume: With thousands of entries, we need a system that can grow.
Performance: Rendering and clustering thousands of markers in the browser severely impacts JS performance.
Data transfer: Sending all point data to the client isn’t scalable.
Real-time UX: We wanted clusters to update as users moved the map, without overloading their device.
Volume: With thousands of entries, we need a system that can grow.
How we solved it
We used geohashing to group nearby points together at varying levels of precision.
A geohash is a short alphanumeric string that encodes a geographic location. What makes geohashes especially useful for clustering is their hierarchical nature: each additional character in the geohash increases the precision and narrows down the location.
For example, the geohash u173z7 is a more precise location within the larger area defined by u173, and so on.
This property allows us to group entries dynamically depending on the zoom level, shorter hashes represent larger clusters, longer hashes zoom in to finer detail.
Each new photo entry is geotagged and stored as a watcher_entry. From there, we generate clusters and store them in a separate geo_clusters table using the beste/latlon-geohash package.

Each entry generates 12 cluster records, one for each geohash level (from 1 to 12). So with 10.000 photo uploads, we’re managing around 100.000 geo_cluster entries.
Each cluster contains:
- The geohash
- Zoom level (hash_length)
- Number of points in that cluster
- A calculated centroid (lat/lng)
The geohash
Zoom level (hash_length)
Number of points in that cluster
A calculated centroid (lat/lng)
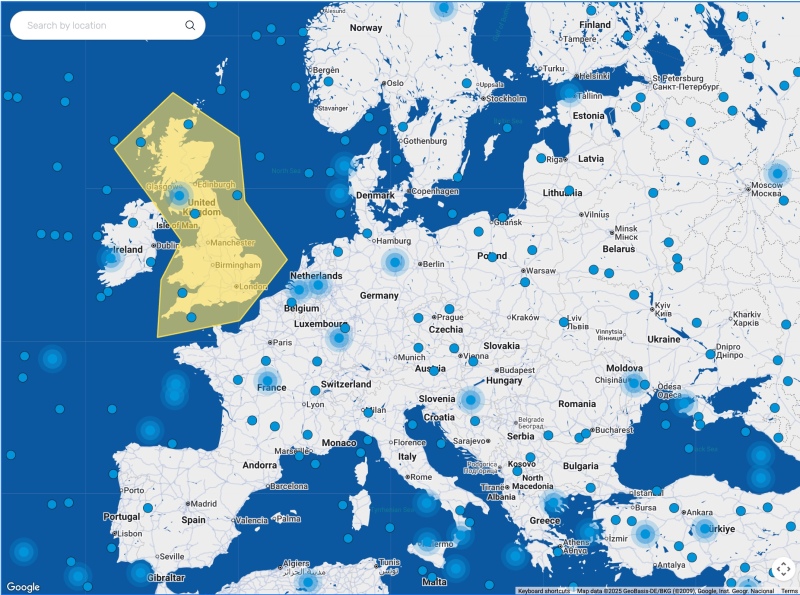
On map move or zoom, the Vue.js frontend requests only the relevant clusters from Meilisearch, using its geosearch functionality to select entries within the map bounds and a matching hash length.
The result? A fast, scalable map that shows meaningful clusters at every zoom level, without overwhelming the browser.
The tech stack behind the scenes
Here’s how it all fits together:
- Laravel Observers: When a watcher_entry is added, an observer updates the geo_clusters table accordingly—incrementing cluster sizes and recalculating centroids.
- Meilisearch: Clusters are indexed and queried using its fast geo search.
- Vue.js & Google Maps: The frontend queries for the visible area and renders clusters based on zoom.
- Filament Admin Panel: Used to manage entries, draw “bonus zones”, and trigger updates.
Laravel Observers: When a watcher_entry is added, an observer updates the geo_clusters table accordingly—incrementing cluster sizes and recalculating centroids.
Meilisearch: Clusters are indexed and queried using its fast geo search.
Vue.js & Google Maps: The frontend queries for the visible area and renders clusters based on zoom.
Filament Admin Panel: Used to manage entries, draw “bonus zones”, and trigger updates.
We also created a custom Filament field that lets admins draw polygon zones on the map. These zones award double points for entries submitted inside them. To detect whether an entry falls inside such a zone, we use the mjaschen/phpgeo package.
Limitations (and what’s next)
No system is without trade-offs. While server-side clustering significantly improves performance and scalability, it does introduce some new challenges:
- Filtering complexity: Fine-grained filtering, like showing only entries from a specific user, time period, or status, becomes more complex. Since clusters are precomputed and not tied to dynamic query parameters, applying detailed filters means recalculating or bypassing the clustering logic altogether.
- Reload on map movement: Each pan or zoom event triggers a full reload of the cluster data. This keeps the map accurate, but can result in minor loading delays on slower connections.
- Initial load in new areas: When zooming out or jumping to a different region, there may be a brief moment where no clusters are shown until new data is fetched.
Filtering complexity: Fine-grained filtering, like showing only entries from a specific user, time period, or status, becomes more complex. Since clusters are precomputed and not tied to dynamic query parameters, applying detailed filters means recalculating or bypassing the clustering logic altogether.
Reload on map movement: Each pan or zoom event triggers a full reload of the cluster data. This keeps the map accurate, but can result in minor loading delays on slower connections.
Initial load in new areas: When zooming out or jumping to a different region, there may be a brief moment where no clusters are shown until new data is fetched.
These limitations are acceptable in our current context, but we’re exploring improvements, like hybrid client/server clustering or background data prefetching, to smooth out the user experience even further.
Wrapping up
User-generated mapping data is powerful, but handling it efficiently takes more than just good frontend code.
By pushing clustering logic to the server, we can handle large datasets smoothly and deliver a better experience on any device.
And more importantly, we enable a gamified, rewarding way for users to make their world a bit cleaner, one photo at a time.